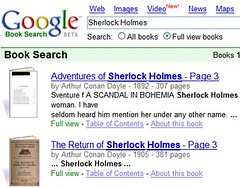
But here is the best part,check the following picture:

Google has scanned every single page, including the empty ones of old books, then they have inserted these images in PDF files. The result are huge files where is impossible to do a search for a word or sentence; you can't look in a PDF for a word that's part of an image. They should have converted each scanned image into text and then create with that text much smaller PDF files with full search capability.
What a waste of HDD space and resources!
If you want searchable texts of the same books, stick with the group that has been doing it for decades. Project Gutenberg.
ReplyDeleteExactly, and a lot more efficiently!
ReplyDeleteTo be fair to Google on this, OCR isn't really accurate enough or fast enough to scan books on such a massive scale, especially when you consider that the older books they are using may have less clear printing, illustrations etc.
ReplyDeleteThat´s why I like Project Gutenberg, because they have taken the time to clean all texts after OCRs and bring us copies of this texts in different formats.
ReplyDeleteIf you look in Project Gutenberg you will find all texts now available in Google in TXT format. So my question is, why this waste of time in a product that is not good. Because to have pictures of each book page is useless if you can´t search in this texts.